

발자취
#14 비정형 데이터 (전문검색) 본문
#01 Like 검색
- 문제점: 조건에 맞는 레코드를 찾아도 검색이 종료되지 않고 계속 전체검색을 진행 → 시스템에 부하를 주는 구조 (만약 AND/OR 형태로 연결되는 쿼리라면? 더 심한 부하..)
#02 전문검색
- 와일드카드 검색(Like)의 대안 → 유사한 결과 제공
- 크게 Stopword 방식과 N-gram 방식으로 나뉨
#02-1 전문검색 - Stopword
- 구분자를 기준으로 분할하는 방식
- 영어에서는 be동사, 정관사, 부정관사, 전치사 등을 제외한 결과(불용어)
- 한글에서는 애매함
#02-2 전문검색 - N-gram
- 기계적으로 N개의 글자단위로 토큰(작은 문자열)으로 나눔
- 2-gram - “아버” “버지” “지가” “방에” “들어” “어가” “가신” “신다”
3-gram - “아버지” “버지가” “들어가” “어가신” “가신다”
4-gram - “아버지가” “들어가신” “어가신다”
5-gram - “들어가신다”
→ 검색결과: 방(X) / 아버지(O) / 들어가(O) / 가신다(O) / 아버(O)
★ 역인덱스 기법: 단어를 보고 어느 문서에 있는지 표로 관리하는 방식
#03 MySQL의 전문검색 실습
1. 전문검색을 기본 4자에서 2자 이상으로 변경

‘ft_min_word_len’가 read only로 설정되어 있기 때문에 설정을 바꿔야 합니다.

my.ini 파일의 설정을 바꿔줬습니다.

my.ini 파일을 우클릭하여 [속성] – [보안] – [편집]에 들어간 후 user의 모든 권한을 허용해줍니다.

‘서비스’ 앱에서 MySQL을 재부팅했습니다.

전문검색의 최소 길이가 2자로 바뀐 것을 확인할 수 있습니다.
2. 테이블 생성 및 전문검색 인덱스 생성
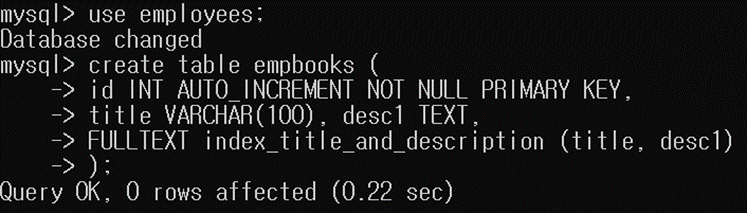
empbooks라는 이름의 테이블을 생성해줬습니다. FULLTEXT 키워드로 전문 검색 인덱스를 만들어줬습니다.

empbooks 테이블에 ‘title’, ‘desc1’의 값을 삽입했습니다.
3. 자연어 모드

empbooks 테이블에서 title, desc1에 “SQL”, “database”라는 문자열이 있는지 검색합니다.

in natural language mode를 작성하여 자연어 모드임을 명시하여 검색해보았습니다. 결과는 같습니다.

자연어 모드로 title과 desc1에 ‘Security’라는 문자열이 있는지 검색했습니다.
4. 이진모드

title과 desc1에 “SQL”라는 단어가 들어가 있고, “database”라는 단어가 들어가 있지 않은 문자열을 검색합니다. 아무런 결과가 나오지 않았습니다.

title과 desc1에 “MySQL”라는 단어가 들어가 있고, “database”라는 단어가 들어가 있지 않은 문자열을 검색했습니다.

title과 desc1에 “database"가 부분적으로 포함되어 있는 문자열을 검색했습니다.
5. 역인덱스 내용 확인하기

innodb_ft_aux_table 변수에 대상 테이블을 명시하여 테이블 단위로 조회할 수 있도록 설정합니다. employees DB의 empbooks 테이블로 설정했습니다.

테이블 최적화 시 테이블 크기에 따라 오랜 시간이 걸릴 수 있기 때문에 전문검색에 대한 최적화만 실행되도록 innodb_optimize_fulltext_only 설정을 했습니다.

optimize table를 통해 ‘empbooks’ 테이블을 최적화했습니다.

전치 텍스트 인덱스로 만들어진 단어를 확인하기 위해 information_schema_innodb_ft_index_table에서 단어, 단어가 표시되는 행의 수, 단어의 특정 인스턴스 위치를 출력했습니다.

default로 설정되어 있는 stopword의 내용을 확인했습니다.
6. N-gram 토크나이저기반 전문검색 인덱스 생성

N-gram 기반으로 전문검색하기 위해 원래의 인덱스를 드롭하고, N-gram 토크나이저기반 전문검색 인덱스를 생성했습니다.
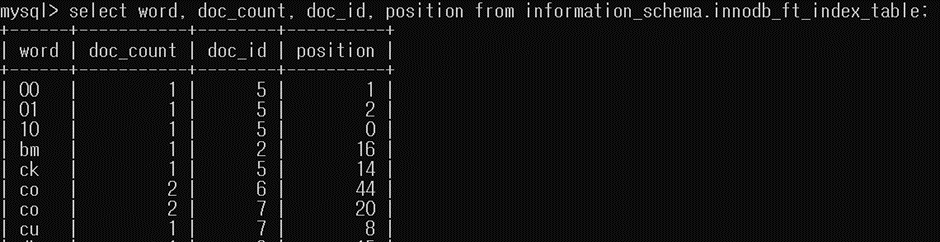
단어, 단어가 표시되는 행의 수, 단어의 특정 인스턴스 위치를 출력했습니다.
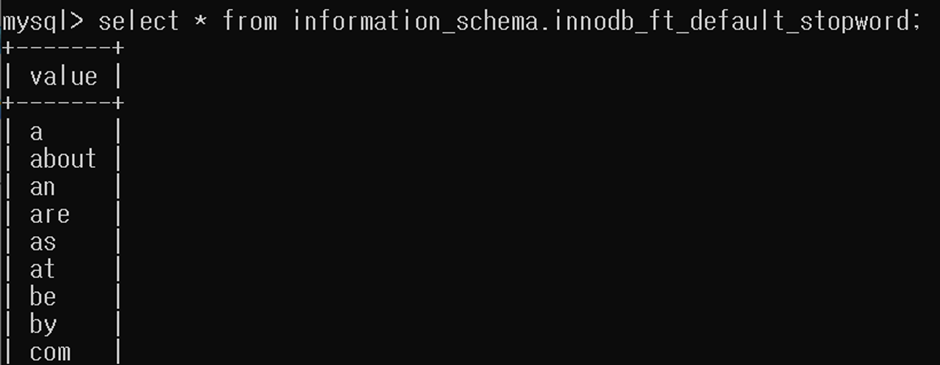
default로 설정되어 있는 stopword의 내용을 확인했습니다.
7. Stopword 테이블 생성

‘stopwords’라는 테이블을 생성하고, innodb_ft_server_stopword_table로 설정했습니다.

기존의 index_title_and_description 인덱스를 삭제한 후, N-gram 토크나이저기반 전문검색 인덱스를 생성했습니다.

title, desc1에 ‘data’가 존재하는지 검색해봤습니다.
'3-1 > 데이터베이스' 카테고리의 다른 글
| #15 JDBC 실습 (0) | 2023.08.12 |
|---|---|
| #13 반정형데이터 (NoSQL, JSON) (0) | 2023.08.12 |
| #12 역정규화, DML 실습 4 (0) | 2023.08.12 |
| #11 모델링2 (테이블 최적화, 정규형), 서브쿼리 (0) | 2023.08.12 |
| #10 DML 실습 3 (Group by, having, charset/collation) (0) | 2023.08.12 |



